Blob data can be exported using PowerShell in a simple way, by querying the data with Ado.Net – SqlClient and then using a BinaryWriter to write it on local hard drive.
This is how we can use PowerShell to export SQL Blob data to file.
## Export of "larger" Sql Server Blob to file
## with GetBytes-Stream.
# Configuration data
$Server = ".\SQL105CTP3"; # SQL Server Instance.
$Database = "ToDO";
$Dest = "D:\Export\"; # Path to export to.
$bufferSize = 8192; # Stream buffer size in bytes.
# Select-Statement for name & blob
# with filter.
$Sql = "SELECT [FileName]
,[Document]
FROM Production.Document
WHERE FileExtension = '.xlsx'";
# Open ADO.NET Connection
$con = New-Object Data.SqlClient.SqlConnection;
$con.ConnectionString = "Data Source=$Server;" +
"Integrated Security=True;" +
"Initial Catalog=$Database";
$con.Open();
# New Command and Reader
$cmd = New-Object Data.SqlClient.SqlCommand $Sql, $con;
$rd = $cmd.ExecuteReader();
# Create a byte array for the stream.
$out = [array]::CreateInstance('Byte', $bufferSize)
# Looping through records
While ($rd.Read())
{
Write-Output ("Exporting: {0}" -f $rd.GetString(0));
# New BinaryWriter
$fs = New-Object System.IO.FileStream ($Dest + $rd.GetString(0)), Create, Write;
$bw = New-Object System.IO.BinaryWriter $fs;
$start = 0;
# Read first byte stream
$received = $rd.GetBytes(1, $start, $out, 0, $bufferSize - 1);
While ($received -gt 0)
{
$bw.Write($out, 0, $received);
$bw.Flush();
$start += $received;
# Read next byte stream
$received = $rd.GetBytes(1, $start, $out, 0, $bufferSize - 1);
}
$bw.Close();
$fs.Close();
}
# Closing & Disposing all objects
$fs.Dispose();
$rd.Close();
$cmd.Dispose();
$con.Close();
Write-Output ("Finished");
Server and Database Name is hard coded in this script. To make it parametrize, add these in first line;
We want to save multiple type of data, documents, image, audio or video. BLOB data type can be used to store this kind of data but it’s limited to 2GB in size. BLOB data slows down database performance and takes significant resources to read. For detail, refer here ;
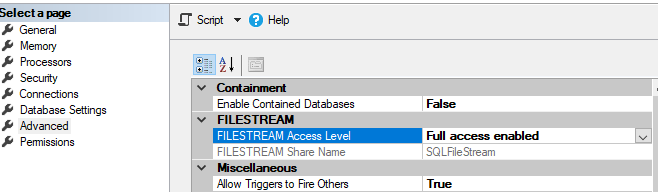
Filestream allows storing these large documents onto the file system itself. There is not limit on storage as compared to 2GB in BLOB storage. Application can access these files using NTFS streaming API. Filestream is not a SQL Server data type to store data.
Filestream does not use the buffer pool memory for caching these objects. If we cache these large objects in the SQL Server memory, it will cause issues for normal database processing. Therefore, FILESTREAM provides caching at the system cache providing performance benefits without affecting core SQL Server performance.
This is how to enable Filestream feature in SQL server;
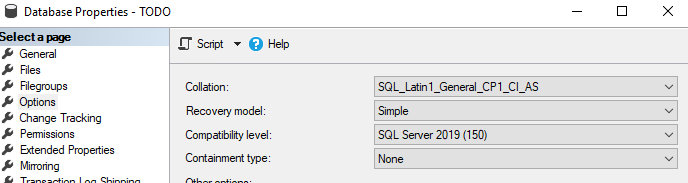
Since I will be doing a lot of inserts/update/delete so I am going to change recovery mode of selected database to “Simple”.
Make sure that you have enable FILESTREAM on database level;
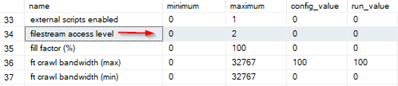
Checking the status of Filestream;
--check filestream status
USE master
Go
EXEC sp_configure
Go
0 = FILESTREAM is disabled.
1 = only T-SQL access to FILESTREAM data is allowed.
2 = T-SQL access and local streaming access is allowed.
3 = T-SQL access and local and remote streaming access is allowed.
You can also use this query to check status;
exec sp_configure 'filestream access level'
I am going to create my first table with filestream enabled;
--Create a table to work with Filestream
USE TODO
GO
CREATE TABLE [dbo].[Document](
[Doc_Num] uniqueidentifier ROWGUIDCOL unique NOT NULL DEFAULT newsequentialid(),
[Extension] [varchar](50) NULL,
[FileName] [varchar](200) NULL,
[FileSize] numeric(10,5),
[Doc_Content] [varbinary](max) FILESTREAM
) ON [PRIMARY]
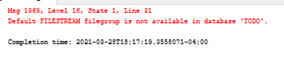
Oops. I got this error;
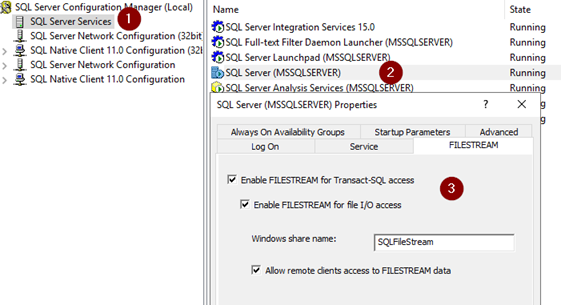
I haven’t enabled Filestream feature in SQL server. Open SQL Server Configuration manager. Right click on SQL Server Services, properties and FileSTREAM.
Restart SQL server service.
Re-run table creation query. This time you will see this error;
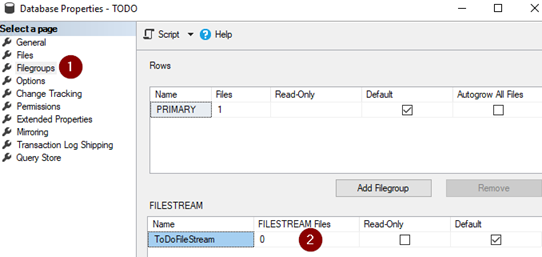
What it means that we have not created File group. Remember Filestream require its own File groups. Right click on your database;
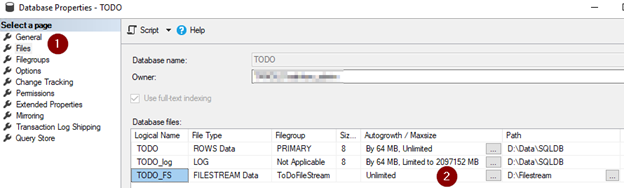
After creating filegroup, open database properties again and click on files. Click on Add to add new file and connect with previously created filegroup.
Navigate to your filesystem path and you should see this;
As shown in the above image, the $FSLOG directory and the filestream.hdr file have been created. $FSLOG is like SQL server T-Log, and filestream.hdr contains metadata of FILESTREAM. Make sure that you do not change or edit those files.
re-run our table creation sql script. This time table should be created successfully.
It’s time to add a new excel document in this table. Run following sql script;
--insert a new excel document
INSERT [dbo].[Document1] ([Extension] ,[FileName], [FileSize], [Doc_Content] )
SELECT 'xlsx', 'SampleExcelDoc.xlsx', 10, [Doc_Data].*
FROM OPENROWSET
(BULK 'D:\SimpleExcelDoc.xlsx', SINGLE_BLOB) [Doc_Data]
Run this statement;
SELECT * FROM [dbo].[Document]
Here is the file on file system;
This file can be opened directly with compatible application program, in this example Excel. Right click, open with and select Excel. When we insert the document using the FILESTREAM feature, SQL Server copies the file into the FILESTREAM path. It does not change the file properties.
To access Filestream data using managed API, we need to figure out Filestream content path. Here is the script;
--access Filestream data using managed API
SELECT Doc_Content.PathName() AS FilePath, *
FROM [dbo].[Document]
You should see these results;
To delete a document from Filestream container, run this;
--delete files from Filestream container.
USE TODO
GO
DELETE FROM dbo.Document
WHERE Doc_Num = '658020B3-1690-EB11-90BB-00155D717606'
In this case, we can see that file still exists for FILESTREAM document. SQL Server removes the old files using the garbage collection process. This process will remove the old file if it is no longer required by the SQL Server. Do you remember about a folder, $log into the FILESTREAM path. It works similar to a transaction log in the SQL Server database.
SQL Server has a particular internal filestream_tombstone table, which contains an entry for this old file.
SELECT * FROM sys.internal_tables where name like ‘filestream_tomb%’
The garbage collection process removes the old file only if there is no entry for the file in the filestream_tombstone table. We cannot see the content of this filestream_tombstone table. However, if you wish to do so, use the DAC connection.
The database recovery model plays an essential role in the entry in the filestream_tombstone table.
Simple recovery mode: In a database in simple recovery model, the file is removed on next checkpoint
Full recovery model: If the database is in full recovery mode, we need to perform a transaction log backup to remove this file automatically
We can run the garbage collector process file manually to remove the files from the container before the automatic garbage collector process cleans the file. We can do it using ‘sp_filestream_force_garbage_collection’ stored procedure.
It’s a common understanding that BLOB column is used to store documents. If we are not using File stream feature, then the data is stored in primary file group and storage limit is 2GB. This approach is handy but slows down database performance and takes significant resources to read data.
Here is a quick example;
--create a new blob table
CREATE TABLE [dbo].[TraditionalBlobTable](
[ID] [int] IDENTITY(1,1) NOT NULL,
[BlobDataCol] [varbinary](max) NOT NULL
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
Insert some data in this table, i am inserting excel file;
--insert excel file in table
INSERT TraditionalBlobTable([BlobDataCol])
SELECT [Doc_Data].*
FROM OPENROWSET
(BULK 'C:\Test.xlsx', SINGLE_BLOB) [Doc_Data]
SELECT * FROM [ToDo].[dbo].[TraditionalBlobTable]
Let’s see how many tables have blob data column in our database;
--how to identify all sql server tables with blob columns
SELECT o.[name], o.[object_id ], c.[object_id ], c.[name], t.[name]
FROM sys.all_columns c
INNER JOIN sys.all_objects o
ON c.object_id = o.object_id
INNER JOIN sys.types t
ON c.system_type_id = t.system_type_id
WHERE c.system_type_id IN (35, 165, 99, 34, 173)
AND o.[name] NOT LIKE 'sys%'
AND o.[name] <> 'dtproperties'
AND o.[type] = 'U'
GO
We are using OLE Automation here to get this data out and store in a file. The first step is to turn on OLE automation procedure;
--turn on ole automation procedure
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
sp_configure 'Ole Automation Procedures', 1;
GO
RECONFIGURE;
GO
Now to the real meat, creating file on file system;
declare @init int
declare @file varbinary(max);
SELECT @file = BlobDataCol FROM TODO.dbo.TraditionalBlobTable
declare @filepath nvarchar(4000) = N'c:\business\myfile.xlsx'
EXEC sp_OACreate 'ADODB.Stream', @init OUTPUT; -- An instace created
EXEC sp_OASetProperty @init, 'Type', 1;
EXEC sp_OAMethod @init, 'Open'; -- Calling a method
EXEC sp_OAMethod @init, 'Write', NULL, @file; -- Calling a method
EXEC sp_OAMethod @init, 'SaveToFile', NULL, @filepath, 2; -- Calling a method
EXEC sp_OAMethod @init, 'Close'; -- Calling a method
EXEC sp_OADestroy @init; -- Closed the resources
Check you file system, the file should be there;
As a security best practice, turn off OLE automation procedure;
--turn off ole automation procedure
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
sp_configure 'Ole Automation Procedures', 0;
GO
RECONFIGURE;
GO