One of my favorite pianist;
https://en.wikipedia.org/wiki/Ludwig_van_Beethoven
Source, Ingest, Prepare, Analyze and Consume
I am running WordPress as Azure App service. My current configuration for the technology stack is;

I did a Site health check on WordPress dashboard; Tools->Site Health, WordPress site health status shows that I am running an older version of PHP.
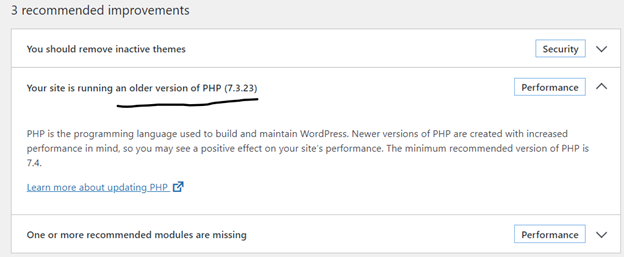
I figured I should be changing my Stack settings from .NET to PHP. I made the change hoping it wouldn’t break the application;
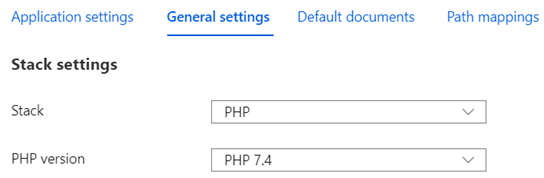
Technology stack is changed from .NET to PHP without any issues.
I went back to WordPress dashboard and ran Site Health. PHP version issue solved.
If someone is running WordPress on Linux, this is a good reference;
I like windows snip and sketch tool. The only draw back, you take a snapshot and if you want to draw rectangle around an area, it’s not possible in this tool. The snapshot has to be copied into MS Paint or Power Point to annotate. It’s kind a two step process.
The alternative is to use Greenshot which is a full featured snipping tool. Greenshot does come with an editor where you can easily add arrows, text, shapes, blur out/pixelate sensitive information.
Greenshot automatically copy the screenshot to the clipboard. At the time of installation it gets registered with windows and always available in the taskbar. If I need to edit a screenshot, I can right-click the greenshot icon and choose: Open Image from clipboard to access it in the editor. Once done, I then either save the image there or choose copy to clipboard, to send the edited version back to the clipboard, ready to be pasted somewhere else.
Here is an example;
Donate:

Just out of curiosity, here is top level comparison; first one is managed instance, second one is Single database;
Top level comparison;
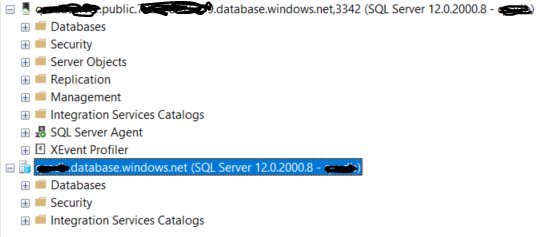
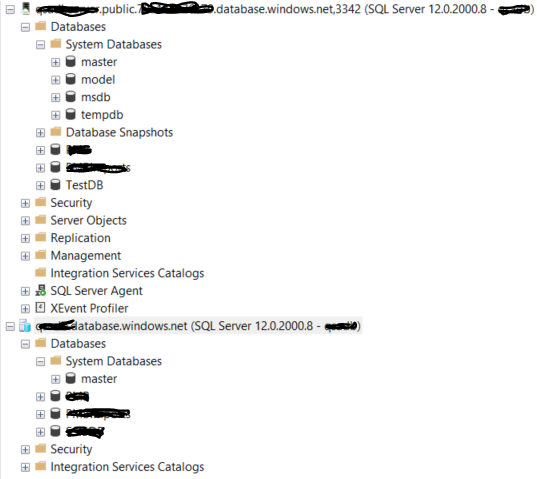
Databases level comparison;
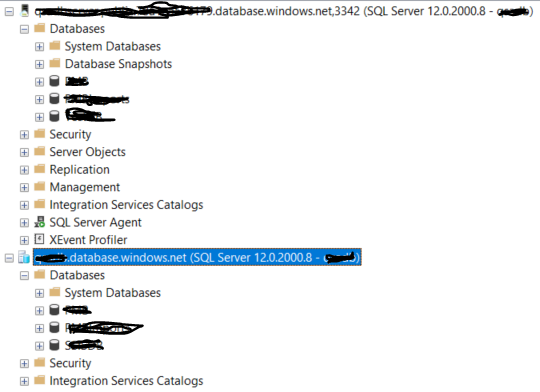
System level databases;
Single database has just master database;
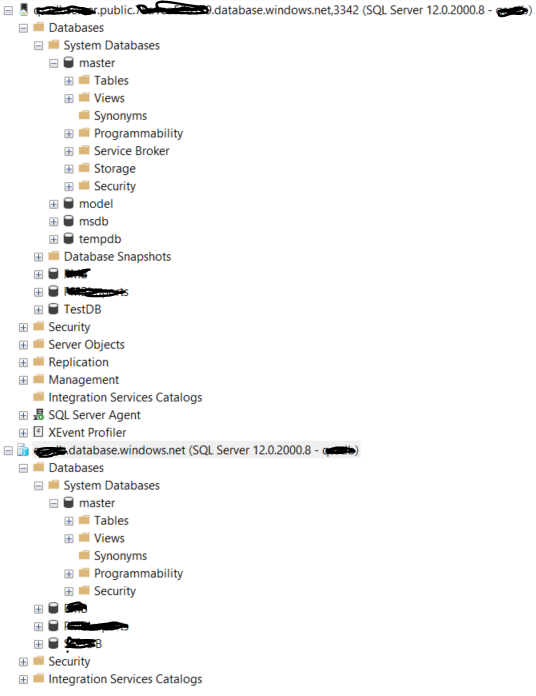
master database object layout
System level security
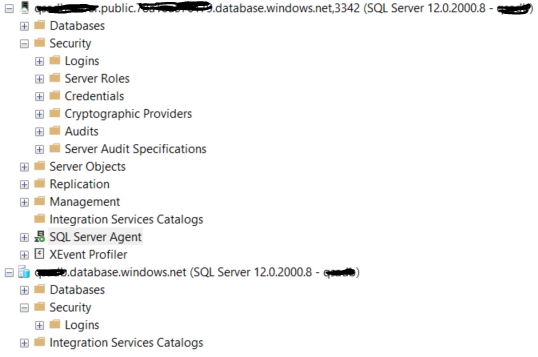
Single database does not have these root level objects;
Server Objects, Replication, Management, SQL Server Agent, XEvent Profiler
Integration Services Catalogs doesn’t exists on both services. Azure Data Factory integration services need to be provisioned to create SSIS database under Integration Services Catalogs.
Reporting services does not exists here. Power BI integrated Reporting services needs to be provisioned.
<ng-template>
It’s a template element that Angular uses with structural directives (*ngIf, *ngFor, [ngSwitch] and custom directives).
These template elements only work in the presence of structural directives. Angular wraps the host element (to which the directive is applied) inside <ng-template> and consumes the <ng-template> in the finished DOM by replacing it with diagnostic comments.
Resources