We can use Regular Expression to find and replace, valid with all versions of SSMS
Find what: {.+}
Replace with: ‘\1’,
Look in: Selection
Expand Find Option
Use: Regular expression (checked)
That regular expression indicates find everything and remember what we found Replace everything we found \1 by wrapping it with tic marks and a comma.
If you have more complex requirements, the right chevron next to the drop down arrow on Find what lists the regular expression dialect SSMS/Visual Studio understands
SQL Server 2012 has two new analytical functions, LEAD() AND LAG(). These functions return data from Next row (LEAD) and Previous row (LAG) of the same dataset without using self-join.
Let’s go with an example;
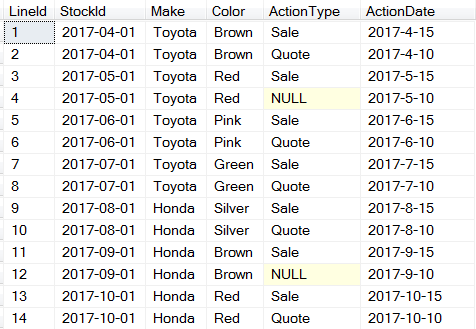
This is my initial dataset;
Here is the query to create this dataset;
IF OBJECT_ID('tempdb..#SampleDataSet') is not null drop table #SampleDataSet
SELECT *
INTO #SampleDataSet
FROM
(
SELECT 1 LineId, '2017-04-01' StockId, 'Toyota' AS Make, 'Brown' AS Color, 'Sale' AS ActionType, '2017-4-15' ActionDate UNION
SELECT 2 LineId, '2017-04-01' StockId, 'Toyota' AS Make, 'Brown' AS Color, 'Quote' AS ActionType, '2017-4-10' ActionDate UNION
SELECT 3 LineId, '2017-05-01' StockId,'Toyota' AS Make, 'Red' AS Color, 'Sale' AS ActionType, '2017-5-15' ActionDate UNION
SELECT 4 LineId, '2017-05-01' StockId, 'Toyota' AS Make, 'Red' AS Color, NULL AS ActionType, '2017-5-10' ActionDate UNION
SELECT 5 LineId, '2017-06-01' StockId, 'Toyota' AS Make, 'Pink' AS Color, 'Sale' AS ActionType, '2017-6-15' ActionDate UNION
SELECT 6 LineId, '2017-06-01' StockId, 'Toyota' AS Make, 'Pink' AS Color, 'Quote' AS ActionType, '2017-6-10' ActionDate UNION
SELECT 7 LineId, '2017-07-01' StockId, 'Toyota' AS Make, 'Green' AS Color, 'Sale' AS ActionType, '2017-7-15' ActionDate UNION
SELECT 8 LineId, '2017-07-01' StockId, 'Toyota' AS Make, 'Green' AS Color, 'Quote' AS ActionType, '2017-7-10' ActionDate UNION
SELECT 9 LineId, '2017-08-01' StockId, 'Honda' AS Make, 'Silver' AS Color, 'Sale' AS ActionType, '2017-8-15' ActionDate UNION
SELECT 10 LineId, '2017-08-01' StockId, 'Honda' AS Make, 'Silver' AS Color, 'Quote' AS ActionType, '2017-8-10' ActionDate UNION
SELECT 11 LineId, '2017-09-01' StockId, 'Honda' AS Make, 'Brown' AS Color, 'Sale' AS ActionType, '2017-9-15' ActionDate UNION
SELECT 12 LineId, '2017-09-01' StockId, 'Honda' AS Make, 'Brown' AS Color, NULL AS ActionType, '2017-9-10' ActionDate UNION
SELECT 13 LineId, '2017-10-01' StockId, 'Honda' AS Make, 'Red' AS Color, 'Sale' AS ActionType, '2017-10-15' ActionDate UNION
SELECT 14 LineId, '2017-10-01' StockId, 'Honda' AS Make, 'Red' AS Color, 'Quote' AS ActionType, '2017-10-10' ActionDate
) src
WHERE 1=1
/*
This is my initial dataset
*/
SELECT * FROM #SampleDataSet src
I am adding SeqCount and Seq column to identify each group of car (make and color) and each action in the group. LAG and Lead values of LineId column are used to demonstrate function output.
SELECT
src.LineId, src.StockId,
ROW_NUMBER() OVER (PARTITION BY StockId ORDER BY ActionDate DESC) Seq,
COUNT(*) OVER (PARTITION BY StockId) SeqCount,
src.Make, src.Color, src.ActionType, src.ActionDate,
LEAD(src.LineId) OVER (ORDER BY src.LineId) LeadValue,
LAG(src.LineId) OVER (ORDER BY src.LineId) LagValue
FROM #SampleDataSet src
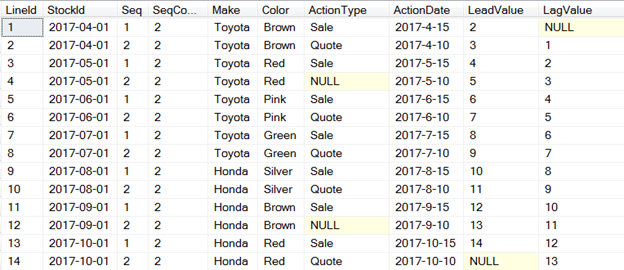
This is the output of above query;
You can see the application of LEAD() and LAG() function in last two columns on the right side of above dataset.
One of the possible application of this function. As a business rule every quote action must be preceded by sale action in a car dealer dataset. If quote action is null in a group, fix it.
SELECT
src.StockId, src.Seq, src.SeqCount, src.Make, src.Color, src.ActionType,
CASE WHEN src.LeadValue = 'Sale' AND src.ActionType IS NULL THEN 'Quote' ELSE src.ActionType END dActionType,
src.ActionDate, src.LeadValue, src.LagValue
FROM
(
--Dataset transformation
SELECT
src.StockId,
ROW_NUMBER() OVER (PARTITION BY StockId ORDER BY ActionDate DESC) Seq,
COUNT(*) OVER (PARTITION BY StockId) SeqCount,
src.Make, src.Color, src.ActionType, src.ActionDate,
LEAD(ActionType) OVER (ORDER BY ActionDate DESC) LeadValue,
LAG(ActionType) OVER (ORDER BY ActionDate DESC) LagValue
FROM #SampleDataSet src
) src
WHERE 1=1
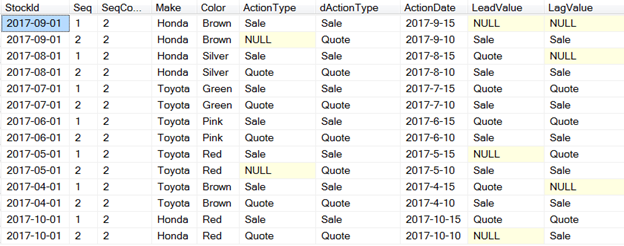
Here is the output;
dActionType is a derived column that has all the correct sequence of actions with the help of Lead() and LAG() function.
Today I have received this error on a remote server connecting from my local computer;
A network-related or instance-specific error occurred while establishing a connection to SQL Server. The server was not found or was not accessible. Verify that the instance name is correct and the SQL server is configured to allow remote connections. (provider: Named Pipes, Provider, error:40 – Could not open a connection to SQL Server) (Microsoft SQL Server, Error: 2).
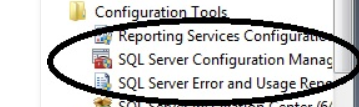
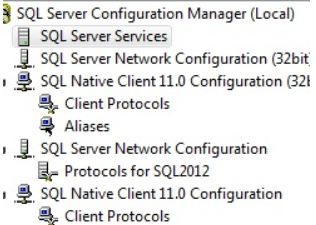
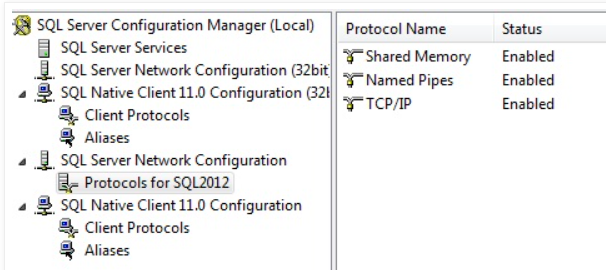
To fix this error goto start menu–> go to Microsoft Sql Server –> go to configurations folder and click on sql server configuration manager. check below image.
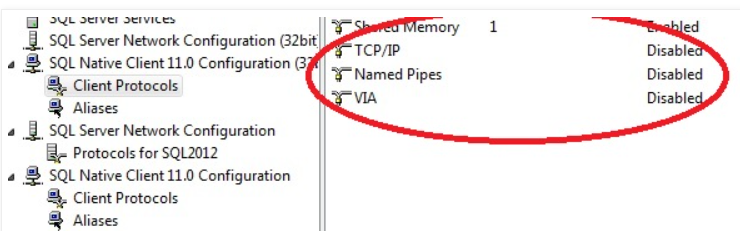
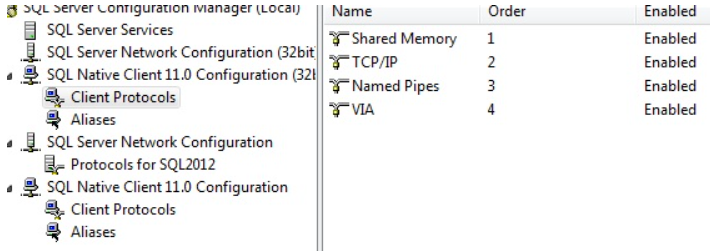
Expand Sql Native client 11.0 Configuration manager. In client protocols you will see TCP/IP, named Pipes,Via disabled, enable those
Expand Server Network Configuration In Protocols for Sql Server here Enable Shared,Named,TCP/IP
Expand Sql Native client 11.0 Configuration manager. In client protocols you will see TCP/IP, named Pipes,Via disabled, enable those and restart the Sql related services. Now the error fixed.
Follow these steps to verify Access Database Engine (ACE Driver) installation;
Double check to make sure you did install the x64 version of Microsoft Access Database Engine here – http://www.microsoft.com/download/en/details.aspx?id=13255. Please note that only one version x64 –OR– x86 can be installed, not both.
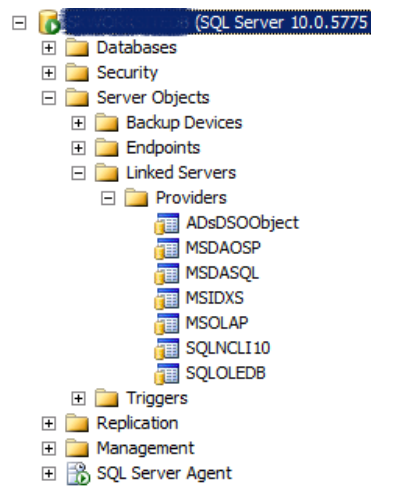
Here is a SQL Server x64 server with the Microsoft Access Database Engine x32 installed – see it does not show up.
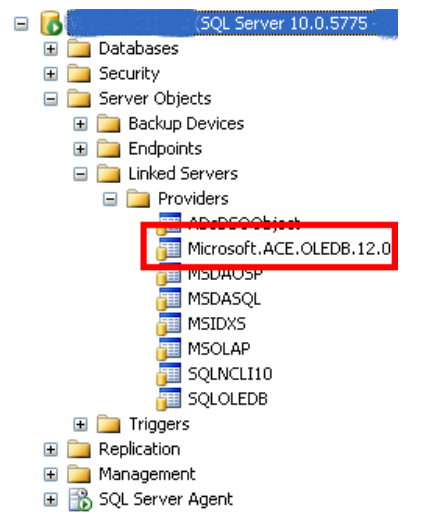
Here is the same server with the Microsoft Access Database Engine x64 installed – see how it shows up.
I do not know of a query to get a list of the providers – however if you look in the registry at
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL10.MSSQLSERVER\Providers and check for the key Microsoft.ACE.OLEDB.12.0
This will tell you that it is installed. If you have a 32-bit version installed on a 64-bit box you would need to look under the Wow6432Node, that key would be HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\Microsoft SQL Server\MSSQL10.MSSQLSERVER\Providers.
You would have to make sure that both SQL Server and the ODBC/OLEDB driver are the same bitwise either both x64 or x32.
declare @DB sysname = 'MyDB';
select * from msdb.dbo.restorehistory where destination_database_name = @DB;
To view all databases;
WITH LastRestores AS
(
SELECT
DatabaseName = [d].[name] ,
[d].[create_date] ,
[d].[compatibility_level] ,
[d].[collation_name] ,
r.*,
RowNum = ROW_NUMBER() OVER (PARTITION BY d.Name ORDER BY r.[restore_date] DESC)
FROM master.sys.databases d
LEFT OUTER JOIN msdb.dbo.[restorehistory] r ON r.[destination_database_name] = d.Name
)
SELECT *
FROM [LastRestores]
WHERE [RowNum] = 1